DDPM原理
DDPM(Denoising Diffusion Probabilistic Models)是一种生成模型,它通过模拟数据的扩散过程来生成新的数据样本。
DDPM通过一个随时间增加噪声的扩散过程和一个逐步去除噪声的生成过程来模拟数据分布。其核心在于训练一个去噪声模型,该模型学习如何从加噪声的数据中恢复原始数据。
这个过程分为两个主要部分:
- 一个是扩散过程,它逐步将数据加噪声,直到数据完全转化为噪声;
- 另一个是去噪声过程,它逐步从噪声中恢复出数据。
DDPM模型的训练目标是学习如何有效地进行去噪声,以便能够从随机噪声中生成高质量的数据样本。
扩散过程
贝叶斯公式
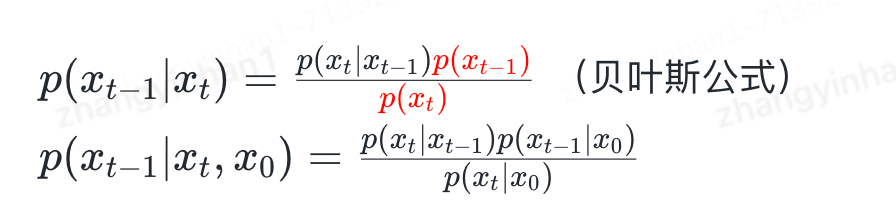
马尔可夫过程
扩散过程可以被视为一系列的马尔可夫链步骤,每一步都向数据中添加一定量的高斯噪声。
给定一个初始数据样本 x 0 x_0 x0,扩散过程可以表示为:
x t = α t x t − 1 + 1 − α t ϵ t x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{1 - \alpha_t} \epsilon_t xt=αtxt−1+1−αtϵt
- x t x_t xt:表示在时间步骤 t t t的数据。
- x t − 1 x_{t-1} xt−1:表示在时间步骤 t − 1 t-1 t−1的数据。
- ϵ t \epsilon_t ϵt是从标准正态分布 N ( 0 , I ) N(0, I) N(0,I)中采样的噪声
- α t \alpha_t αt是一个介于0和1之间的预先定义的系数,用于控制噪声的加入程度 α t \alpha_t αt随时间递减,表示噪声量的增加。这个过程逐渐增加数据中的噪声,直到数据完全转化为噪声。
去噪声过程
去噪声过程的目标是学习一个模型,该模型能够预测给定带噪声数据
x
t
x_t
xt时的原始数据
x
0
x_0
x0。
这个过程可以被视为扩散过程的逆过程,目标是从简单的噪声分布中重建出原始数据,通过训练一个神经网络 ϵ θ \epsilon_\theta ϵθ来预测给定噪声数据 x t x_t xt时的噪声 ϵ \epsilon ϵ来实现。
在这个过程的开始,我们从标准正态分布中采样一个点 x T x_T xT 作为起点,即:
x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, \mathbf{I}) xT∼N(0,I)
这里的 N ( 0 , I ) \mathcal{N}(0, \mathbf{I}) N(0,I)表示均值为0,协方差矩阵为单位矩阵 I \mathbf{I} I的多维正态分布。这个采样点 x T x_T xT 将作为去噪过程的输入,通过模型逐步去除噪声,最终生成数据 x 0 x_0 x0。
逆扩散迭代公式可以表示为:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) x_{t-1} = \frac{1}{\sqrt{\alpha_t}} (x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta(x_t, t)) xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))
其中:
- x t − 1 x_{t-1} xt−1:是我们希望恢复的,在时间步骤 t − 1 t-1 t−1的去噪后的数据。
- x t x_t xt:是当前步骤中的含噪数据。
- α t \alpha_t αt:同上,控制每一步加入噪声的量。
- α ˉ t \bar{\alpha}_t αˉt:是直到时间步骤 t t t的所有 α \alpha α值的累乘,表示到目前为止整体噪声量的累积。
- ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t):是神经网络预测的噪声,这个网络试图从噪声数据 x t x_t xt中恢复出原始的噪声 ϵ \epsilon ϵ。
数据从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)的高斯分布中采样获得" 指的是初始化去噪过程的步骤,即从一个多维标准正态分布中采样一个起始点。
多维标准正态分布的概率密度函数(PDF)为:
p
(
x
)
=
1
(
2
π
)
d
/
2
exp
(
−
1
2
x
T
x
)
p(x) = \frac{1}{(2\pi)^{d/2}} \exp\left(-\frac{1}{2} x^T x\right)
p(x)=(2π)d/21exp(−21xTx)
其中, x x x 是一个 d d d维向量, d d d 是数据的维度, x T x^T xT是 x x x 的转置。
- 这个分布有一个中心在原点,协方差矩阵为单位矩阵,意味着各个维度上的随机变量是独立且同分布的。
通过从这个分布中采样,我们可以得到一个随机向量 x T x_T xT,它的每个分量都是独立的标准正态分布变量。这个向量 x T x_T xT 是去噪过程的输入,模型将从这个噪声分布中逐步重建出原始数据。
训练目标
DDPM的训练目标是最小化去噪声过程中的预测噪声的误差,模型被训练来预测在每一步扩散过程中加入的噪声 ϵ t \epsilon_t ϵt,而不是直接预测原始数据 x 0 x_0 x0。
这可以通过最小化以下损失函数来实现:
L = E t , x 0 , ϵ t [ ∣ ϵ t − ϵ θ ( x t , t ) ∣ 2 2 ] L = \mathbb{E}_{t, x_0, \epsilon_t}\left[ | \epsilon_t - \epsilon_\theta(x_t, t) |_2^2 \right] L=Et,x0,ϵt[∣ϵt−ϵθ(xt,t)∣22]
其中, ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)是模型对加入的噪声的预测, ϵ t \epsilon_t ϵt是实际加入的噪声, θ \theta θ表示模型参数。
模型推导
- 初始化:从训练数据中选择一个样本 x 0 x_0 x0作为扩散过程的起点。
- 扩散过程:通过上述扩散公式,逐步加入噪声,直到数据完全转化为噪声。
- 去噪声过程:使用模型 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)来预测每一步中加入的噪声,并逐步从噪声数据中恢复出原始数据。
- 训练:通过最小化损失函数 L L L来训练模型,使其能够准确预测每一步中加入的噪声。
- DDPM通过这种方式训练生成模型,使其能够从纯噪声中生成高质量的数据样本。这个过程的关键在于,通过逐步加入和去除噪声,模型学习到了数据的内在结构和分布,从而能够生成新的、逼真的数据样本。
DDIM
DDIM的核心思想
DDIM的核心思想是改进生成过程,使其在每一步都显式地依赖于原始数据 x 0 x_0 x0,而非完全依赖于模型的去噪能力。这种方法允许模型在较少的步骤中更快地生成数据,因为它直接利用了关于原始数据的信息。
DDIM的去噪声过程
假设我们有一个噪声级别为 t t t的数据 x t x_t xt,DDIM的目标是计算一个更少噪声的版本 x t − 1 x_{t-1} xt−1。
与DDPM不同,DDIM使用一个确定性的映射而非条件高斯分布。
这个映射可以表示为:
x t − 1 = α t − 1 ∗ x t − 1 − α t ϵ θ ( x t , t ) α t + 1 − α t − 1 ∗ ϵ θ ( x t , t ) x_{t-1} = \sqrt{\alpha_{t-1}} * {\frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta(x_t, t)}{\sqrt{\alpha_t}}} + \sqrt{1-\alpha_{t-1}} * \epsilon_\theta(x_t, t) xt−1=αt−1∗αtxt−1−αtϵθ(xt,t)+1−αt−1∗ϵθ(xt,t)
其中, α t \alpha_t αt是预定义的噪声水平系数, ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)是模型预测的噪声,与DDPM中的相同。
逐项解释这个公式中的每个部分:
-
x t − 1 x_{t-1} xt−1:这是我们希望计算的目标,即在时间步 t − 1 t-1 t−1的数据。这个数据应该比 x t x_t xt有更少的噪声,我们通过应用确定性映射来计算它。
-
x t x_t xt:这是当前步骤中的数据,它包含了噪声级别为 t t t的信息。
-
α t \alpha_t αt 和 α t − 1 \alpha_{t-1} αt−1:这些是预定义的系数,它们与每一步中加入或去除的噪声量有关。这些系数帮助我们控制数据中噪声的量。在扩散过程中, α t \alpha_t αt是逐渐减小的,表示数据中噪声的增加。
-
1 − α t \sqrt{1-\alpha_t} 1−αt和 1 − α t − 1 \sqrt{1-\alpha_{t-1}} 1−αt−1:这些根号项代表噪声的标准差。它们说明了在每一步中,噪声是如何影响数据的。
-
ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t):这是模型预测的噪声,即去噪声模型试图从 x t x_t xt中恢复出的噪声。这个预测用于帮助我们在去噪声过程中更准确地恢复出原始数据
这个公式的核心在于两个主要部分:
-
去除噪声:首先,我们从当前的数据 x t x_t xt中去除预测的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t),这是通过 x t − 1 − α t ϵ θ ( x t , t ) α t \frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta(x_t, t)}{\sqrt{\alpha_t}} αtxt−1−αtϵθ(xt,t)这部分实现的。这一步的目的是尽可能地恢复出在没有噪声 t t t的情况下的数据。
-
添加适量噪声:然后,我们添加适当量的噪声以达到 t − 1 t-1 t−1时刻的噪声水平,这是通过 1 − α t − 1 ϵ θ ( x t , t ) \sqrt{1-\alpha_{t-1}} \epsilon_\theta(x_t, t) 1−αt−1ϵθ(xt,t)这部分实现的。这一步确保了我们不是简单地去除所有噪声,而是逐步接近原始数据的过程。
推导过程
-
从噪声中恢复:这一步是基于DDPM的去噪声模型,模型预测给定噪声数据 x t x_t xt时的噪声 ϵ \epsilon ϵ。
-
确定性映射:与DDPM使用的随机过程不同,DDIM采用了一个确定性的映射来计算下一步的数据 x t − 1 x_{t-1} xt−1。这种方法减少了生成过程中的随机性,允许更快地收敛。
算法优势
- 效率:由于DDIM在每一步都直接利用了关于原始数据的信息,它可以在较少的步骤中生成数据,从而提高了效率。
- 稳定性:确定性的映射减少了生成过程中的随机性,使得生成的数据更加稳定和一致。
Score-based
Score-based生成模型,也称为Score Matching模型,是一种基于能量的生成模型,它通过学习数据分布的梯度场(即分数函数)来生成新的样本。这个模型的核心是估计概率分布的分数,即概率密度函数对数据的梯度。以下是Score-based模型的基本推导。
假设我们有一个数据集 { x i } \{x_i\} {xi},数据点 x i x_i xi 从一个未知的数据生成分布 p data ( x ) p_{\text{data}}(x) pdata(x) 中采样得到。我们的目标是学习一个模型分布 p model ( x ; θ ) p_{\text{model}}(x; \theta) pmodel(x;θ),使其尽可能接近真实的数据分布 p data ( x ) p_{\text{data}}(x) pdata(x),其中 θ \theta θ 是模型参数。
在Score-based模型中,我们不直接学习 p model ( x ; θ ) p_{\text{model}}(x; \theta) pmodel(x;θ),而是学习数据分布的分数函数 s ( x ; θ ) s(x; \theta) s(x;θ),其中 s ( x ; θ ) = ∇ x log p model ( x ; θ ) s(x; \theta) = \nabla_x \log p_{\text{model}}(x; \theta) s(x;θ)=∇xlogpmodel(x;θ)。
Fisher得分匹配
为了学习分数函数,我们可以使用Fisher得分匹配(Fisher Score Matching)。其目标是最小化模型分数和数据分数之间的平方误差:
J ( θ ) = 1 2 E x ∼ p data ( x ) [ ∥ s ( x ; θ ) − ∇ x log p data ( x ) ∥ 2 ] J(\theta) = \frac{1}{2} \mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \left\| s(x; \theta) - \nabla_x \log p_{\text{data}}(x) \right\|^2 \right] J(θ)=21Ex∼pdata(x)[∥s(x;θ)−∇xlogpdata(x)∥2]
然而, ∇ x log p data ( x ) \nabla_x \log p_{\text{data}}(x) ∇xlogpdata(x) 通常是未知的,所以我们不能直接优化这个目标函数。一个解决方案是使用分数函数的定义和积分的链式法则来重写目标函数,得到一个只依赖于模型分数的目标函数:
J ( θ ) = 1 2 E x ∼ p data ( x ) [ ∥ s ( x ; θ ) ∥ 2 ] − E x ∼ p data ( x ) [ div s ( x ; θ ) ] + const J(\theta) = \frac{1}{2} \mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \left\| s(x; \theta) \right\|^2 \right] - \mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \text{div} \, s(x; \theta) \right] + \text{const} J(θ)=21Ex∼pdata(x)[∥s(x;θ)∥2]−Ex∼pdata(x)[divs(x;θ)]+const
其中 div s ( x ; θ ) \text{div} \, s(x; \theta) divs(x;θ) 是分数函数的散度,也被称为Stein’s Unbiased Risk Estimator (SURE)。
优化
在实践中,我们通常使用一个参数化的模型(如神经网络)来表示分数函数 s ( x ; θ ) s(x; \theta) s(x;θ),并使用随机梯度下降(SGD)或其变体来最小化目标函数 J ( θ ) J(\theta) J(θ)。
生成样本
一旦我们学习到了分数函数 s ( x ; θ ) s(x; \theta) s(x;θ),就可以使用Langevin动力学来生成新的样本。从一个随机初始化的点 x 0 x_0 x0 开始,我们可以迭代地应用以下更新规则:
x t + 1 = x t + ϵ 2 2 s ( x t ; θ ) + ϵ z t , z t ∼ N ( 0 , I ) x_{t+1} = x_t + \frac{\epsilon^2}{2} s(x_t; \theta) + \epsilon z_t, \quad z_t \sim \mathcal{N}(0, I) xt+1=xt+2ϵ2s(xt;θ)+ϵzt,zt∼N(0,I)
其中 ϵ \epsilon ϵ 是一个小的步长, z t z_t zt 是从标准正态分布中采样的噪声。
通过这个迭代过程,我们可以从噪声中生成出符合数据分布的样本。
请注意,这里的推导是非常高层次的概述,具体实现中会有更复杂的细节,比如如何选择合适的学习率、如何确保数值稳定性、如何处理高维数据等。此外,实际应用中还会涉及到更高级的技术,如变分下界的优化、随机微分方程的应用等。
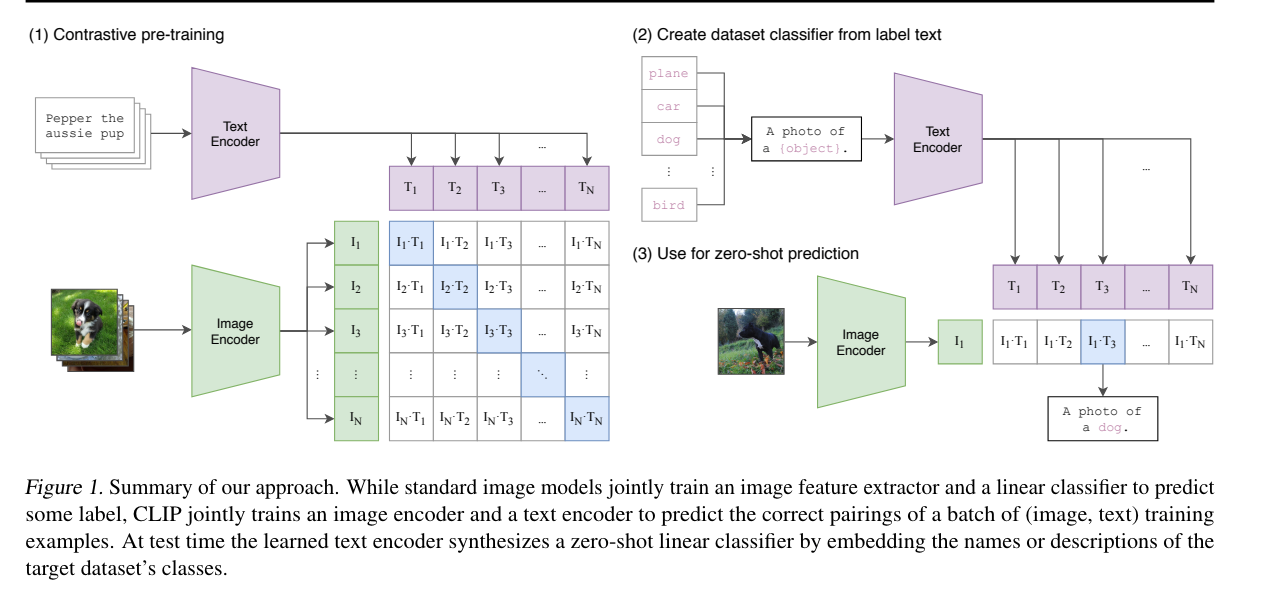
CLIP
预训练任务:即预测哪个文本描述对应当前图像
代码流程:

Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred.
-
学习联合表征向量:CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder
-
N个真实的pair:to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch
-
N 2 − N N^2 − N N2−N to minimizie the cosine similarity of the embeddings of the N 2 − N N^2 − N N2−N incorrect pairings.
-
InfoNCE 对比损失:We optimize a symmetric cross entropy loss over these similarity scores
CLIP的改动:
- CLIP去掉了ConVIRT中text transformation(指均匀从text中采样句子),因为CLIP数据集中有很多只出现过一次的(image,text);
- CLIP的image transformation只用了resize和squared crop;
- CLIP loss中的temperature参数τ是可学的
LLaVA
架构

- 输入的图片使用CLIP预训练的ViT编码,然后通过一个线性层W(可训练的)映射到语言空间(变成token和文本的token进行拼接)
- 和minigpt4的区别是不需要复杂的Q-Former结构,但是需要微调语言模型,minigpt不需要训练语言模型。
训练:
训练过程主要分为两轮:
(1)Pre-training for Feature Alignment,frozen视觉vit和语言llm模型,从CC3M数据中过滤了595K图像-文本对,Xinstruct是单轮训练,只训练Project W权重。
(2)Fine-tuning End-to-End,只frozen视觉的vit权重,更新Project和LLM大语言模型的权重。分成2个任务:
-
多模态chatbot:
用158K的数据训练(其中58K对话数据、23K详细描述、77K复杂推理),分成3种问答形式(Conversion,Detailed description,Complex reasoning),其中Conversion采用多轮对话形式,其他采用单轮。 -
Science QA:采用单轮问答形式训练。

-
输入模版,只在response上计算loss

GLIDE
- 代码开源
两种不同的引导策略:CLIP Guide和Classifier-Free Guide。
- 实验发现,Classifier-Free Guide在人类评估者眼中无论是在照片真实感还是标题相似性方面都更受青睐,并且能够产生逼真的样本。
Classifier-Free Guide策略的优点是不需要单独训练一个分类器,仅需将类别标签替换为一个空标签,并将标签预测概率的梯度替换为基于文本标签与空标签之间条件分布的差异
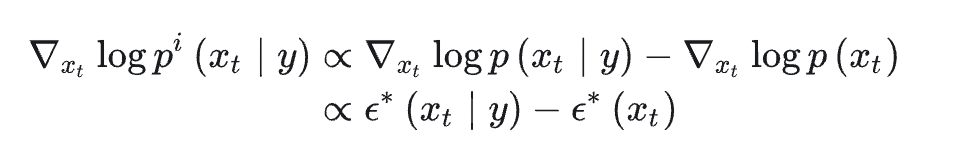
CLIP Guide 则是通过对无条件扩散模型预测的噪声应用梯度修正来实现:
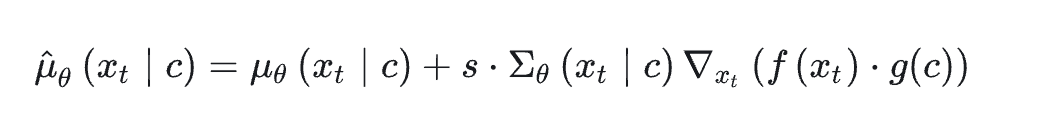
代码
-
https://github.com/openai/glide-text2im/blob/main/glide_text2im/xf.py
-
token embedding:Transformer + 一个全连接层进行编码
-
postion embedding:可学习的,直接和token embedding相加
-
timestep embedding:再和加完postion后的token emb相加,由残差块和注意力块组成
-
上采样是插值,下采样是卷积
-
注意力层的qkv空间位置编码
Unet
- Unet结构(都带上timestep embedding):
- 每层input_block:残差块+注意力块,最后一个是残差块+下采样块
- 每层middle_block:残差块+注意力块 + 残差块
- 每层output_block:残差块+注意力块,最后一个是残差块+上采样块
def forward(self, x, timesteps, y=None):
"""
Apply the model to an input batch.
:param x: an [N x C x ...] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:param y: an [N] Tensor of labels, if class-conditional.
:return: an [N x C x ...] Tensor of outputs.
"""
assert (y is not None) == (
self.num_classes is not None
), "must specify y if and only if the model is class-conditional"
hs = []
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
if self.num_classes is not None:
assert y.shape == (x.shape[0],)
emb = emb + self.label_emb(y)。# time emb + label emb
h = x.type(self.dtype)
for module in self.input_blocks:
h = module(h, emb)
hs.append(h)
h = self.middle_block(h, emb)
for module in self.output_blocks:
h = th.cat([h, hs.pop()], dim=1)
h = module(h, emb)
h = h.type(x.dtype)
return self.out(h)
timestep embedding
def timestep_embedding(timesteps, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an [N x dim] Tensor of positional embeddings.
"""
half = dim // 2
freqs = th.exp(
-math.log(max_period) * th.arange(start=0, end=half, dtype=th.float32) / half
).to(device=timesteps.device)
args = timesteps[:, None].float() * freqs[None]
embedding = th.cat([th.cos(args), th.sin(args)], dim=-1)
if dim % 2:
embedding = th.cat([embedding, th.zeros_like(embedding[:, :1])], dim=-1)
return embedding
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
"""
A sequential module that passes timestep embeddings to the children that
support it as an extra input.
为了每一步都带上time embedding
"""
def forward(self, x, emb, encoder_out=None):
for layer in self:
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
elif isinstance(layer, AttentionBlock):
x = layer(x, encoder_out)
else:
x = layer(x)
return x
MultiheadAttention代码
class MultiheadAttention(nn.Module):
def __init__(self, n_ctx, width, heads):
super().__init__()
self.n_ctx = n_ctx
self.width = width
self.heads = heads
self.c_qkv = nn.Linear(width, width * 3)
self.c_proj = nn.Linear(width, width)
self.attention = QKVMultiheadAttention(heads, n_ctx)
def forward(self, x):
x = self.c_qkv(x)
x = self.attention(x)
x = self.c_proj(x)
return x
class QKVMultiheadAttention(nn.Module):
def __init__(self, n_heads: int, n_ctx: int):
super().__init__()
self.n_heads = n_heads
self.n_ctx = n_ctx
def forward(self, qkv):
bs, n_ctx, width = qkv.shape
attn_ch = width // self.n_heads // 3
scale = 1 / math.sqrt(math.sqrt(attn_ch))
qkv = qkv.view(bs, n_ctx, self.n_heads, -1)
q, k, v = th.split(qkv, attn_ch, dim=-1)
weight = th.einsum(
"bthc,bshc->bhts", q * scale, k * scale
) # More stable with f16 than dividing afterwards
wdtype = weight.dtype
weight = th.softmax(weight.float(), dim=-1).type(wdtype)
return th.einsum("bhts,bshc->bthc", weight, v).reshape(bs, n_ctx, -1)
MLP和Res
class ResidualAttentionBlock(nn.Module):
def __init__(
self,
n_ctx: int,
width: int,
heads: int,
):
super().__init__()
self.attn = MultiheadAttention(
n_ctx,
width,
heads,
)
self.ln_1 = LayerNorm(width)
self.mlp = MLP(width)
self.ln_2 = LayerNorm(width)
def forward(self, x: th.Tensor):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class MLP(nn.Module):
def __init__(self, width):
super().__init__()
self.width = width
self.c_fc = nn.Linear(width, width * 4)
self.c_proj = nn.Linear(width * 4, width)
self.gelu = nn.GELU()
def forward(self, x):
return self.c_proj(self.gelu(self.c_fc(x)))
class Transformer(nn.Module):
def __init__(
self,
n_ctx: int,
width: int,
layers: int,
heads: int,
):
super().__init__()
self.n_ctx = n_ctx
self.width = width
self.layers = layers
self.resblocks = nn.ModuleList(
[
ResidualAttentionBlock(
n_ctx,
width,
heads,
)
for _ in range(layers)
]
)
def forward(self, x: th.Tensor):
for block in self.resblocks:
x = block(x)
return x
超分代码
class SuperResText2ImUNet(Text2ImUNet):
"""
A text2im model that performs super-resolution.
Expects an extra kwarg `low_res` to condition on a low-resolution image.
"""
def __init__(self, *args, **kwargs):
if "in_channels" in kwargs:
kwargs = dict(kwargs)
kwargs["in_channels"] = kwargs["in_channels"] * 2
else:
# Curse you, Python. Or really, just curse positional arguments :|.
args = list(args)
args[1] = args[1] * 2
super().__init__(*args, **kwargs)
"""
def forward(self, x, timesteps, low_res=None, **kwargs):
x 是输入的高分辨率特征,timesteps 是时间步参数,low_res 是可选的低分辨率图像。
代码将低分辨率图像 low_res 上采样到与 x 相同的高度和宽度。
上采样使用双线性插值方法(mode="bilinear"),并且 align_corners=False 指定了插值的一种特定方式。
通过 th.cat([x, upsampled], dim=1),将上采样后的低分辨率图像与输入特征 x 在通道维度上(dim=1)拼接。
最后,使用 super().forward(x, timesteps, **kwargs) 调用父类的 forward 方法,并将拼接后的特征图传递进去,完成前向传播。
总的来说,这个类的目的是结合低分辨率图像和其他可能的输入特征(如文本描述),通过超分辨率模型生成高分辨率的图像。这个过程通常用于图像生成任务,其中文本描述帮助模型理解要生成的图像内容,而低分辨率图像提供了一个粗略的视觉基础。
"""
def forward(self, x, timesteps, low_res=None, **kwargs):
_, _, new_height, new_width = x.shape
upsampled = F.interpolate(
low_res, (new_height, new_width), mode="bilinear", align_corners=False
)
x = th.cat([x, upsampled], dim=1)
return super().forward(x, timesteps, **kwargs)
图像修复
"""
执行修复操作:
使用 inpaint_mask 乘以 inpaint_image 来应用掩码,只保留需要修复的区域的图像信息。
其他区域(掩码值为0的区域)将被置为0。
使用 th.cat([x, inpaint_image * inpaint_mask, inpaint_mask], dim=1) 将输入图像 x、处理后的待修复图像区域(inpaint_image * inpaint_mask)、以及掩码 inpaint_mask 在通道维度上(dim=1)拼接起来。这一步骤将原始图像、修复内容和修复区域的信息合并,为模型提供了完整的上下文信息。
"""
def forward(self, x, timesteps, inpaint_image=None, inpaint_mask=None, **kwargs):
if inpaint_image is None:
inpaint_image = th.zeros_like(x)
if inpaint_mask is None:
inpaint_mask = th.zeros_like(x[:, :1])
return super().forward(
th.cat([x, inpaint_image * inpaint_mask, inpaint_mask], dim=1),
timesteps,
**kwargs,
)
def forward(
self,
x,
timesteps,
inpaint_image=None,
inpaint_mask=None,
low_res=None,
**kwargs,
):
if inpaint_image is None:
inpaint_image = th.zeros_like(x)
if inpaint_mask is None:
inpaint_mask = th.zeros_like(x[:, :1])
_, _, new_height, new_width = x.shape
upsampled = F.interpolate(
low_res, (new_height, new_width), mode="bilinear", align_corners=False
)
return super().forward(
th.cat([x, inpaint_image * inpaint_mask, inpaint_mask, upsampled], dim=1),
timesteps,
**kwargs,
)
DALL-E
-
阶段1:先训练一个离散变分自编码器(dVAE),将每张256×256的RGB图像压缩成32×32网格的图像标记,每个标记可以取8192个可能的值。这样做将tranformer的上下文大小减少了192倍,而视觉生成质量没有大幅下降。
-
阶段2:将多达256个BPE编码的文本标记与1024个图像标记(32×32)连接起来,然后训练一个自回归tranformer来模拟文本和图像标记的联合分布。
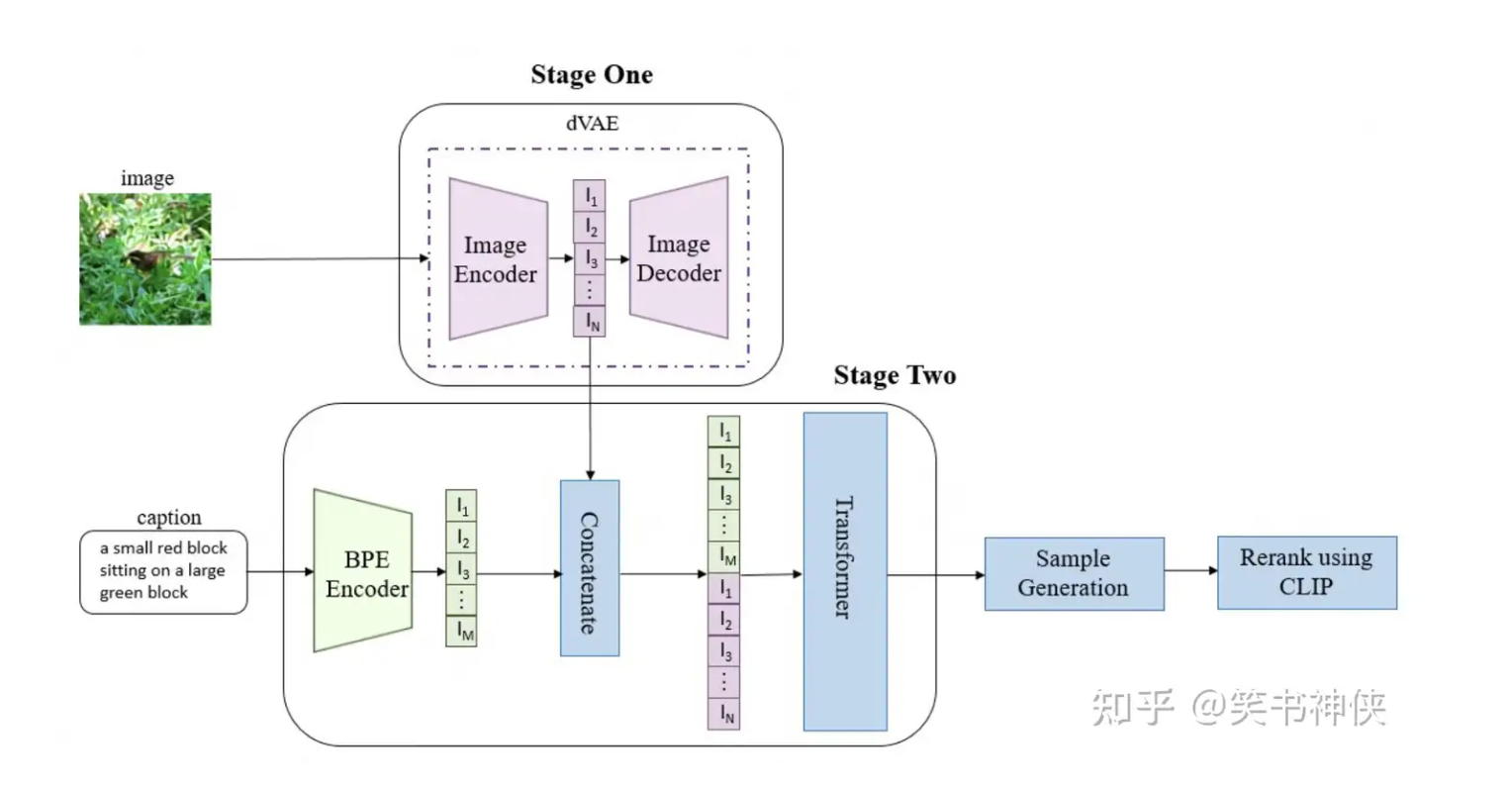
-
文本编码:DALL·E首先利用其BPE编码器将输入的文本描述转换成一组嵌入向量。
-
自回归生成:然后,这些嵌入向量被送入Transformer模型,在自回归的方式下生成图像标记,之后通过离散变分自编码器(dVAE)的解码器解码,生成对应的图像。
-
后处理:最终,通过预先训练好的CLIP模型计算文本描述与生成图像之间的匹配得分,并保留那些匹配得分较高的图像。
-
BPE(Byte Pair Encoding)编码器是一种通过迭代合并频繁出现的字符或字符序列来构建词汇表的方法,这种方法可以有效地处理词汇表外的单词,以及应对语言中的形态变化。
DALL-E 2
- https://zhuanlan.zhihu.com/p/526438544
整体架构
对比学习模型,如CLIP,能够学习到鲁棒的、富含语义和风格的图像表示。为了将这些强有力的图像表示应用于图像生成中,作者提出了一个两阶段模型DALL-E 2:
- 第一阶段:一个先验模型,它可以根据文本标题生成CLIP图像嵌入。以文本为输入,经过CLIP模型,得到图像表示,以此作为先验知识。
- 第二阶段:解码器,它依赖于图像嵌入来生成图像。基于第一阶段的图像表示,经过解码器,生成符合文本描述的图像内容。

-
具体训练过程:

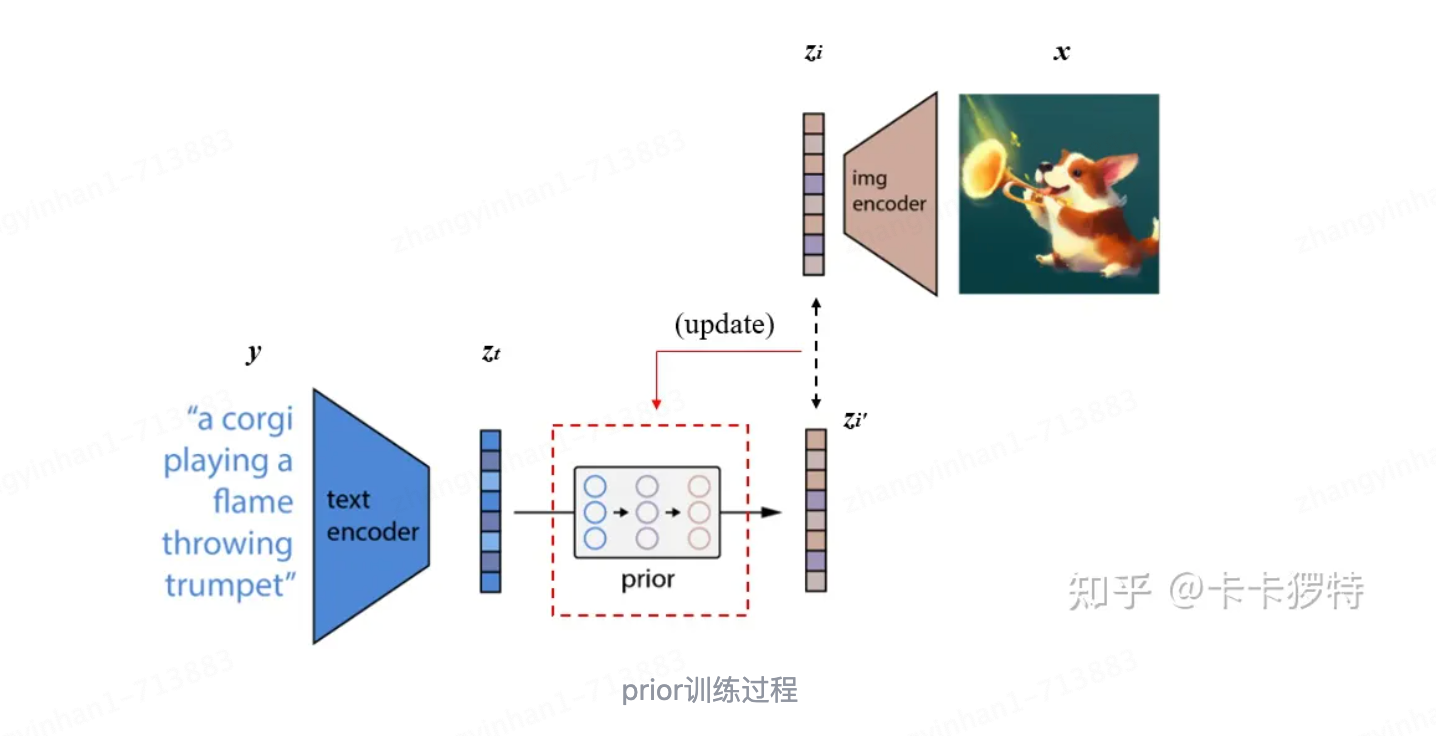

-
论文整体原图,需要分步骤解读
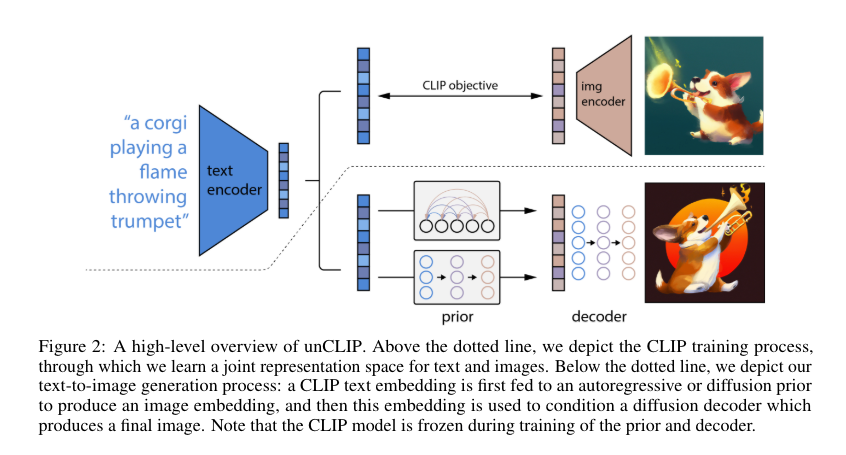
先验知识
尽管解码器可以将CLIP图像嵌入 z i z_i zi转换回图像x,但我们仍需要一个先验模型,它能够根据文本描述 y y y生成 z i z_i zi,这样才能实现从文本描述生成图像的功能
两种策略:
- 为了改善采样质量,对 AR and diffusion的先验知识同时随机drop掉10%的文本控制信息
(1)自回归模型先验:将CLIP图像向量 z i z_i zi转换为一个离散code序列,然后以文本 y y y作为条件约束 ,进行预测。
- 为了更有效地从自回归先验中训练和采样,对应用主成分分析PCA进行降维处理。
- 为什么能进行降维呢?
作者发现,当使用SAM训练CLIP时,CLIP表示空间的秩急剧下降且验证指标稍有提升。相比原来的1024维,仅保留319个主成分,就能保存将近所有的信息。 - 将文本caption的自回归先验知识和CLIP文本向量进行编码作为Prefix,进而达到约束自回归先验的目的。
- 以文本向量 z i z_i zi和图像向量 z t z_t zt的点积约束模型,在更高的点积条件下训练模型,因为较高的文本与图像点积意味着标题更能准确地描述图像。在实际应用中,我们发现从分布的点积前一半(top half)对点积进行采样是有帮助的。
(2)扩散模型先验:使用高斯扩散模型直接建模连续向量 z i z_i zi
使用 the encoded text, the CLIP text embedding, an embedding for the diffusion timestep,the noised CLIP image embedding, and a final embedding 来预测 the unnoised CLIP image embedding
- 没有使用文本和图像的点积,采样生成两个图像向量 z i z_i zi选择与文本向量 z i z_i zi点积更高的那个图像 z i z_i zi
- 预测中使用均方误差作为损失函数
Decoder
使用约束信息作为指导能极大地提升采样质量。
- 因而,作者使用classifier-free guidance,通过对10%的时间序列随机设置CLIP向量为0或是可学习的向量为0,以及随机失活50%的文本信息
为了生成高分辨率图像,作者训练了两个扩散上采样模块:
- 一个用于将64x64分辨率上采样到256x256
- 另一个进一步将256x256分辨率上采样到1024x1024
为了提升上采样模块的鲁棒性,在训练时,分别使用高斯模糊、BSR弱化等处理手段。
text2img
尽管我们训练了一个先验模型来从标题生成CLIP图像嵌入,但这个先验模型对于标题到图像的生成并不是绝对必要的。
- 我们的解码器可以同时基于CLIP图像嵌入和标题进行条件化,但在训练过程中,CLIP图像嵌入有5%的时间会被丢弃,以实现无分类器引导。
- 在采样时,我们可以仅基于标题进行条件化,尽管这种方式的性能不如完全以此方式训练的模型(三种里面效果最差)
- 另一种可能是将CLIP文本嵌入作为图像嵌入输入给解码器
- 另一种方法是将解码器训练为基于CLIP文本嵌入[9]而不是CLIP图像嵌入进行条件化(尽管我们会失去第4节提到的能力)
我们训练了两个模型:
- 一个基于CLIP文本嵌入的小型解码器
- 一个小型非CLIP堆栈(扩散先验和解码器)效果好
DALL-E 3
DALL-E 3的这篇技术报告重点是放在了如何通过合成图像的文本描述(caption)来提升模型的prompt following能力,即生成的图像和输入的text prompt的一致性)
- text2img模型的问题:模型无法生成文本所描述的图像
这个问题主要还是由于训练数据集的图像caption不够准确
- 一方面,图像常规的文本描述往往过于简单(比如COCO数据集),它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等。
- 一方面,图文pair数据质量不够高。目前训练文生图的图像文本对数据集(比如LAION数据集)都是从网页上爬取的,图像的文本描述其实就是alt-text,但是这种文本描述很多是一些不太相关的东西,比如广告
Openai的解决方案:训练一个image captioner(CoCa)来合成图像的caption
- 其中一点是合成caption对文生图模型性能的影响
- 另外一点是探讨训练过程中合成caption和原始caption的最佳混合比例
- 只用原始caption
- 5%的原始caption+95%的合成短caption
- 5%的原始caption+95%的合成长caption
如何评估?
验证模型的prompt following能力,所以采用了CLIP score来评价模型,这里的CLIP score是基于CLIP ViT-B/32来计算生成图像的image embedding和text prompt对应的text embedding的余弦相似度
结论:
- 长caption > 短caption > 原始caption
- 混合比例为95%为最佳
- 由于采用长captin训练的latent diffusion模型,在实际用户输入中大多是短caption,所以使用GPT4将短caption改写成长caption
- DALL-E 3的模型应该类似于SDXL,采用递进式的训练策略(256 -> 512 -> 1024),而且最后也是采用了多尺度训练策略来使模型能够输出各种长宽比的图像
- DALL-E 3额外训练了一个
latent decoder(替换原始的VAE decoder)来提升图像的细节,特别是文字和人脸方面,这个应该是为了解决VAE所产生的图像畸变。这个pixel level扩散模型的condition是VAE的latent
存在的问题:
- 模型在空间位置关系上还是会比较容易出错,当prompt包含一些位置关系描述如"to the left of",模型生成的图像并不一定会符合这样的位置关系,这主要是因为合成的caption在这方面也并不可靠
- 文字生成能力有限。出现多词或者少词的情况,一个可能的原因T5-XXL的tokenizer并不是字符级
- 合成的caption会幻想图像中的重要细节,比如给一幅植物的绘图,image captioner可能会虚构出一个植物并体现在合成的caption上。
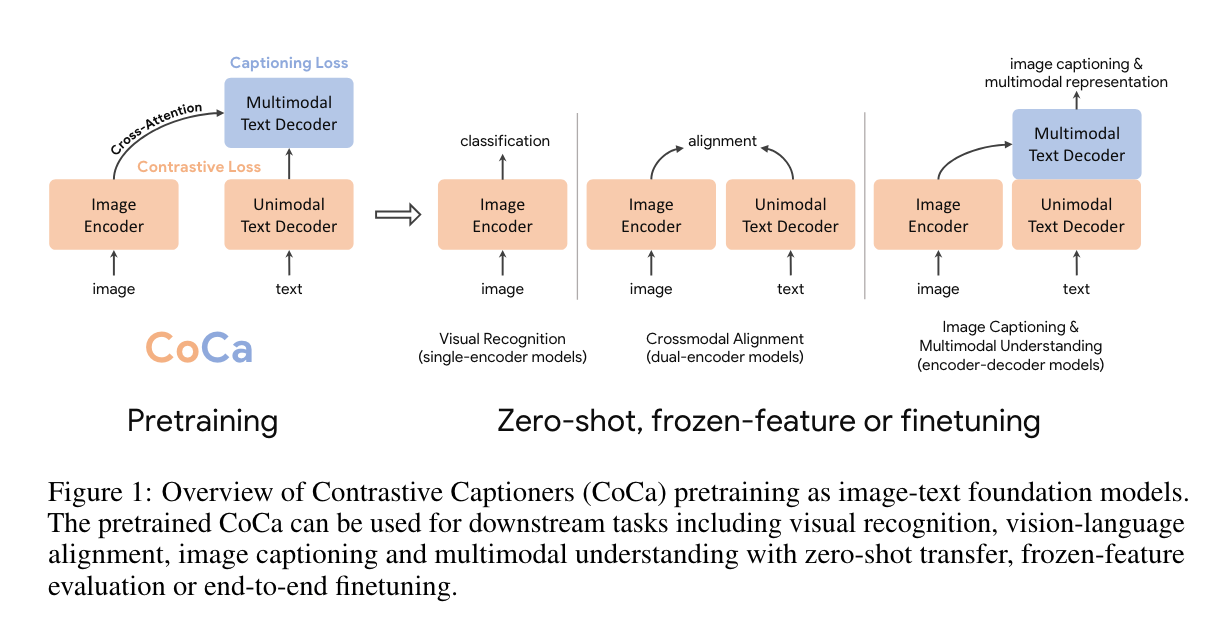
Coca
CoCa在解码器层的前半部分省略了跨注意力机制,以编码单模态文本表示,并将剩余的解码器层级联起来,这些层跨关注图像编码器以生成多模态图像-文本表示。
我们在单模态图像和文本嵌入之间应用对比损失,同时在多模态解码器输出上应用字幕损失,后者预测文本标记自回归地生成。通过共享相同的计算图,这两个训练目标可以高效地计算,开销最小。
- CoCa从头开始端到端预训练,既使用了网络规模的替代文本数据,也使用了标注图像,将所有标签简单地视为文本,无缝地统一了表示学习的自然语言监督。

- 单模态图像和文本嵌入之间使用对比损失
- 在多模态解码器输出上使用text caption 交叉熵损失
Stable Diffusion
Stable Diffusion是一种基于扩散模型的生成模型,它能够生成高质量的图像,并且支持条件生成,比如根据文本描述生成图像。Stable Diffusion结合了扩散模型和变分自编码器(Variational Autoencoder, VAE)的特点,通过一个精心设计的反向过程生成数据。以下是Stable Diffusion的主要原理和组成部分:
原理概述
-
扩散过程:Stable Diffusion的基础是扩散模型,这种模型通过逐步添加噪声将数据(如图像)转换成无结构的噪声。具体来说,这个过程通过多个步骤逐渐增加噪声,每一步都基于高斯分布添加噪声,直到数据完全转变为噪声。
-
变分自编码器(VAE):Stable Diffusion使用VAE来学习数据的压缩表示,这有助于提高模型的效率和生成质量。在扩散过程的开始,使用VAE编码的图像而不是原图,这样可以减少扩散模型需要处理的数据复杂度。
-
去噪过程:与扩散过程相反,去噪过程从噪声中恢复出原始数据。这一过程是通过训练一个神经网络(通常是一个Transformer模型)来完成的,该网络学习如何在每一步中预测并去除噪声,最终恢复出接近原始数据的图像。
-
文本到图像生成:Stable Diffusion通过将文本嵌入作为条件信息输入到去噪过程中,实现了根据文本描述生成图像的功能。这通过使用预训练的文本嵌入模型(如CLIP)来实现,它能够将文本描述转换成与图像内容相关联的嵌入向量。
关键技术和特点
-
CLIP引导:Stable Diffusion使用OpenAI开发的CLIP模型来理解文本和图像之间的关系,这使得它能够根据文本提示生成与之高度相关的图像。
-
去噪预测网络:该网络是Stable Diffusion的核心,负责在去噪过程中预测每一步应该去除多少噪声,以逐步恢复出清晰的图像。
-
高效性和灵活性:Stable Diffusion设计用于高效生成高质量的图像,同时支持多种生成任务,包括条件生成(如文本到图像)、图像到图像转换、图像编辑等。
Diffusion Guidance
Diffusion Model (例如,DDPM)的主要任务是无条件生成图像。如果想控制生成的图像内容就需要conditional diffusion model。
Conditional diffusion model 将额外的条件信息(例如,类别信息,文本)作为模型的输入来学习。那么目前就有两种对diffusion model进行引导的方法。Classifier Guidance 和 Classifier-free guidance。
DDPM + Classifier Guidance
Classifier Guidance核心思路:
- 在diffusion model逆向过程的每一步,用另外一个分类网络对生成的图片进行分类。
- 再基于分类分数和目标类别之间的交叉熵损失计算梯度,用该梯度引导下一步的生成采样。
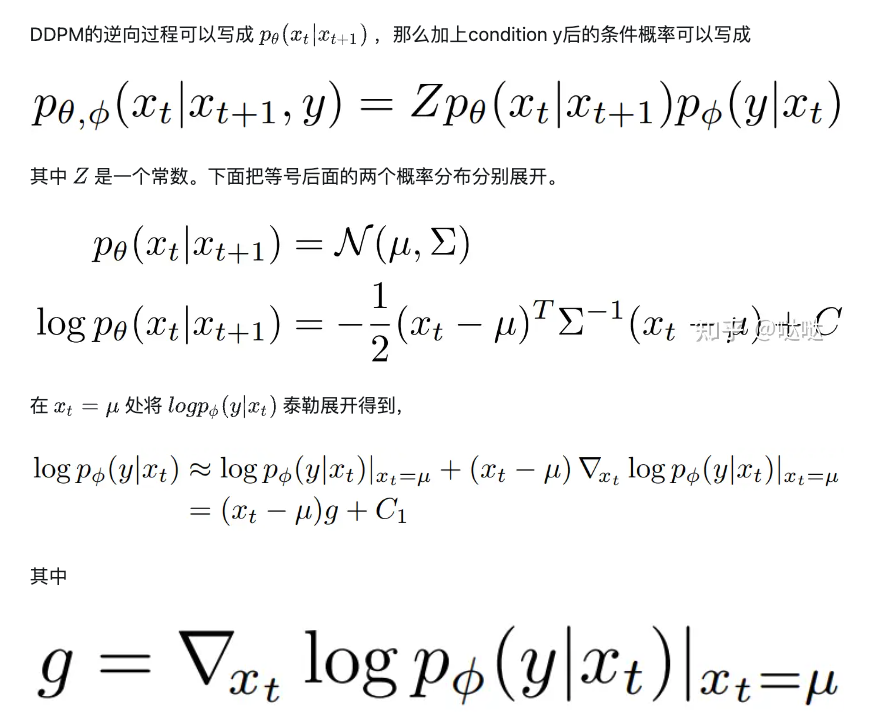

- s是分类器的缩放因子,变化的部分就是加上的这个分类器梯度

- 改变的是采样的分布

DDPM + Classifier (CLIP) Guidance
上面的Classifier Guidance针对的是类别条件,那把分类器替换成CLIP就可以做文本引导的diffusion model。
-
用类别分类器引导:将diffusion model逆过程每一步产生的输入到分类器中得到预测类别的概率与groundturth的类别做交叉熵,再得到梯度信息。
-
用CLIP引导:将diffusion model逆过程每一步产生的输入到CLIP的image encoder中,将文本条件输入到CLIP的text encoder中计算两者的相似度,再得到梯度信息。
DDIM + Classifier Guidance


Classifier-Free Diffusion Guidance
Classifier Guidance 使用显式的分类器引导条件生成有几个问题:
- 一是需要额外训练一个噪声版本的图像分类器。
- 二是该分类器的质量会影响按类别生成的效果。
- 三是通过梯度更新图像会导致对抗攻击效应,生成图像可能会通过人眼不可察觉的细节欺骗分类器,实际上并没有按条件生成。

Classifier-Free Guidance的核心是通过一个隐式分类器来替代显示分类器,而无需直接计算显式分类器及其梯度。
根据贝叶斯公式,分类器的梯度可以用条件生成概率和无条件生成概率表示:

训练时,Classifier-Free Guidance需要训练两个模型:
- 一个是无条件生成模型,另一个是条件生成模型。但这两个模型可以用同一个模型表示,训练时只需要以一定概率将条件置空即可。
详细公式
- 苏神文章:https://kexue.fm/archives/9257/comment-page-1
基本原理
在CFG中,模型被训练来理解如何在给定特定条件(如文本描述)时生成数据,同时也学习如何在没有任何条件的情况下生成数据。
- 生成时,通过调整条件生成和无条件生成之间的平衡,可以引导模型偏向于生成满足特定条件的数据,而无需外部分类器。
公式推导
假设我们有一个条件 ©(例如文本描述),我们想要生成满足这个条件的数据 (x)。
- 我们首先有一个条件生成的概率分布 p ( x ∣ c ) p(x|c) p(x∣c),表示在给定条件 © 下生成数据 (x) 的概率。
- 同时,我们也有一个无条件生成的概率分布 p ( x ) p(x) p(x),表示在没有任何条件的情况下生成数据 (x) 的概率。
在CFG中,生成过程是通过调整这两种分布之间的平衡来进行的。具体来说,我们通过引入一个超参数 (w) 来调整这两种模式的权重,生成的新分布可以表示为:
p cfg ( x ∣ c ) ∝ p ( x ∣ c ) ∗ w ⋅ p ( x ) ∗ ( 1 − w ) p_{\text{cfg}}(x|c) \propto p(x|c) * w \cdot p(x)*{(1-w)} pcfg(x∣c)∝p(x∣c)∗w⋅p(x)∗(1−w)
其中,(w) 是一个大于1的权重,用于控制条件生成和无条件生成之间的平衡。当 (w=1) 时,CFG退化为纯条件生成;随着 (w) 增大,生成过程更加关注于满足条件 ©。
在实践中,我们通常不直接计算上述公式,而是通过调整生成过程中的梯度来实现。给定一个目标(如最小化与目标分布的KL散度),我们可以调整反向过程中的梯度更新步骤,使得在每一步的更新中,生成的数据既考虑到满足条件 © 的需求,也保留了一定程度的随机性(无条件生成的特性)。
Transformer扩散模型 - DiT
- DiT详解
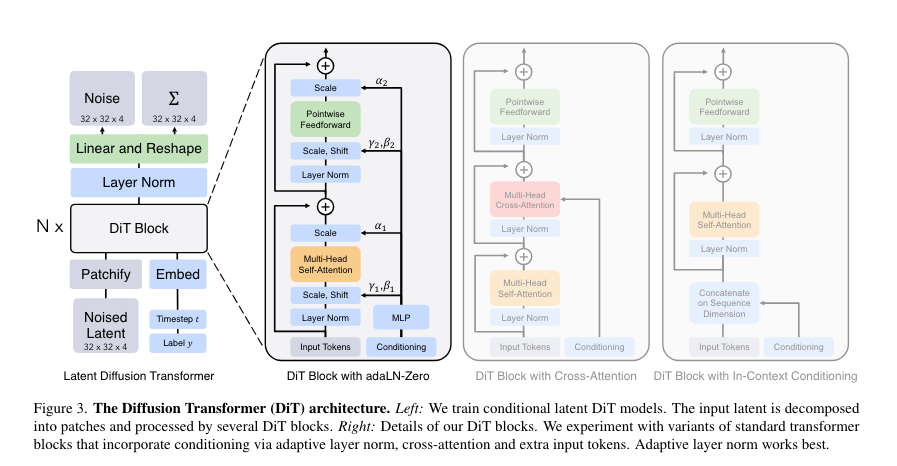

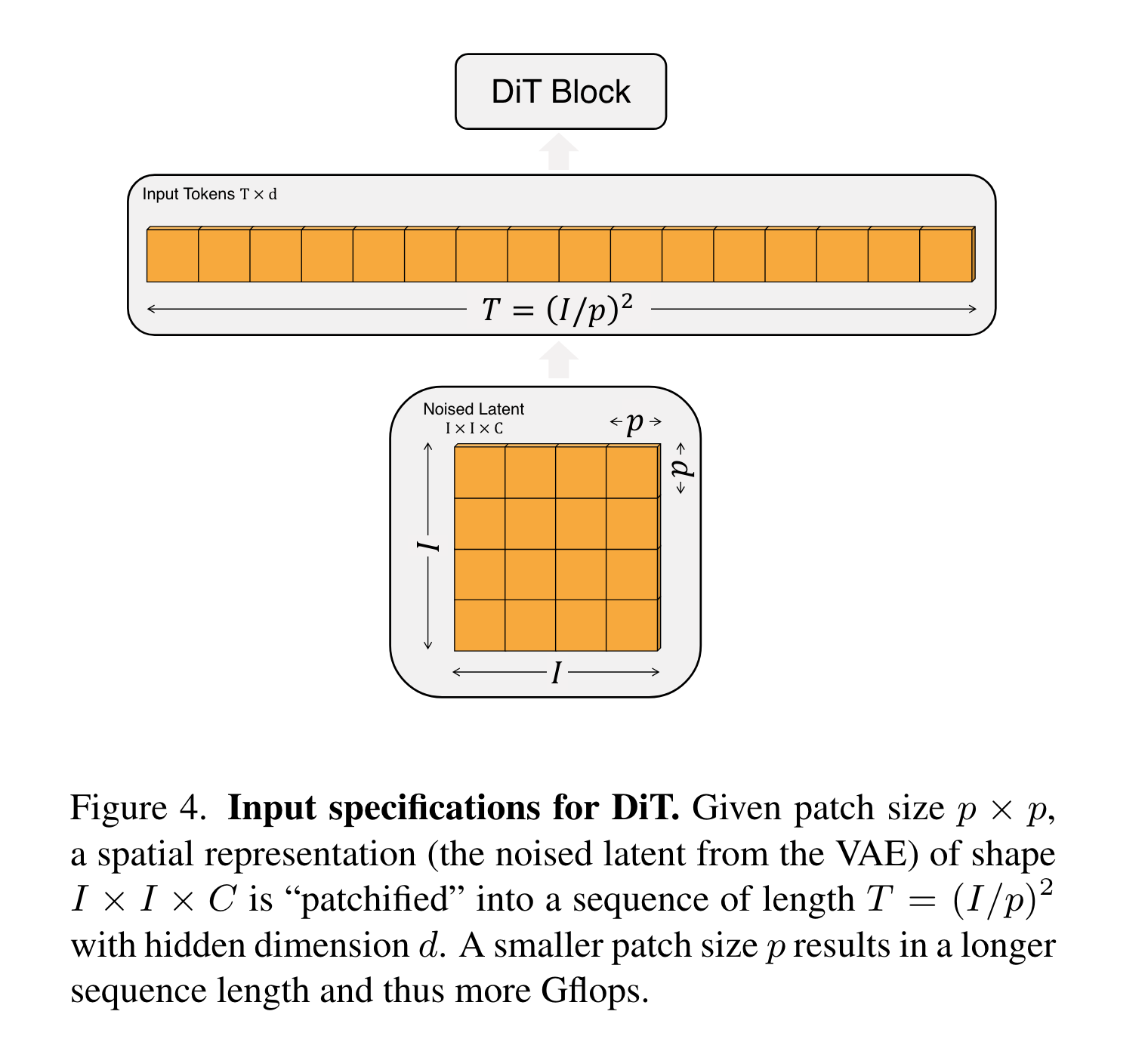
(1)In-context conditioning
(2)Cross-attention block
(3)Adaptive layer norm (adaLN) block
(4)AdaLN-Zero block
(5)DiT scaling
AdaLN
LN的目的是减少训练过程中的内部协变量偏移,通过规范化每个样本在网络层内的激活值来加速训练并提高模型的稳定性。
下面是Layer Normalization的基本数学公式:
给定一个小批量的数据,其中包含(N)个样本,每个样本具有(M)个特征(对于一个给定的层)。对于该层的每个样本 x i x_i xi(其中 i = 1 , 2 , . . . , N i = 1, 2, ..., N i=1,2,...,N),Layer Normalization首先计算该样本的均值 μ i \mu_i μi和方差 σ i 2 \sigma_i^2 σi2:
μ i = 1 M ∑ j = 1 M x i j \mu_i = \frac{1}{M} \sum_{j=1}^{M} x_{ij} μi=M1∑j=1Mxij
σ i 2 = 1 M ∑ j = 1 M ( x i j − μ i ) 2 \sigma_i^2 = \frac{1}{M} \sum_{j=1}^{M} (x_{ij} - \mu_i)^2 σi2=M1∑j=1M(xij−μi)2
其中, x i j x_{ij} xij是第 i i i个样本的第 j j j个特征。
接着,对每个样本的每个特征进行规范化:
x ^ i j = x i j − μ i σ i 2 + ϵ \hat{x}_{ij} = \frac{x_{ij} - \mu_i}{\sqrt{\sigma_i^2 + \epsilon}} x^ij=σi2+ϵxij−μi
这里, ϵ \epsilon ϵ是一个很小的数值,例如 1 0 − 5 10^{-5} 10−5,用来保证分母不为零,增加数值稳定性。
最后,引入了两个可学习的参数,缩放因子 γ \gamma γ和偏移量 β \beta β(这两个参数的维度与每个样本的特征数相同),用于对规范化后的数据进行线性变换:
y i j = γ x ^ i j + β y_{ij} = \gamma \hat{x}_{ij} + \beta yij=γx^ij+β
最终得到的 y i j y_{ij} yij是Layer Normalization的输出,用于下一层的输入。
- Scale(缩放因子)
定义:在Layer Normalization之后应用的乘法因子,用于调整规范化后的数据的尺度。这使得网络可以学习到在规范化过程中最优的数据分布尺度。
目的:缩放因子允许模型恢复那些对于完成特定任务可能是有益的、在规范化过程中被标准化的特征的重要性。
- Shift(偏移量)
定义:在Layer Normalization之后应用的加法项,用于调整规范化后的数据的中心位置。这使得网络可以学习到在规范化过程中最优的数据分布中心。
目的:偏移量允许模型调整数据分布的中心位置,保留或恢复对于完成特定任务可能是有益的特征。
总结来说,Layer Normalization通过计算每个样本的均值和方差,并对每个样本的特征进行规范化,然后通过引入可学习的缩放因子和偏移量进行线性变换,以此来优化训练过程和模型性能。
PixArt
任务分解
PIXART-α将复杂的文本到图像生成任务分解为三个子任务:
(1)Pixel dependency learning
为了生成高质量图像,本文首先在ImageNet上预训练类引导生成模型,这一过程不仅成本低廉,而且能够有效地理解图像内部的像素级依赖性。因为类引导生成模型的架构与文本到图像生成模型架构有兼容性,这种预训练的初始化方式大大提高了训练的效率。
(2)Text-image alignment learning
为了实现文本与图像之间的精确对齐,本文构建了一个包含高概念密度的精确文本-图像对数据集,利用这个数据集,每次训练迭代时能够处理更多的名词,并且相较于以往的数据集,所遇到的歧义显著减少,极大地提高了模型在文本描述与图像对齐方面的训练效率。
(3)High-resolution and aesthetic image generation
为了生成高审美质量的图片,本文使用高质量的审美数据对模型进行微调。因为前两个阶段建立了强大先验知识,这个阶段的收敛速度显著加快。
模型架构
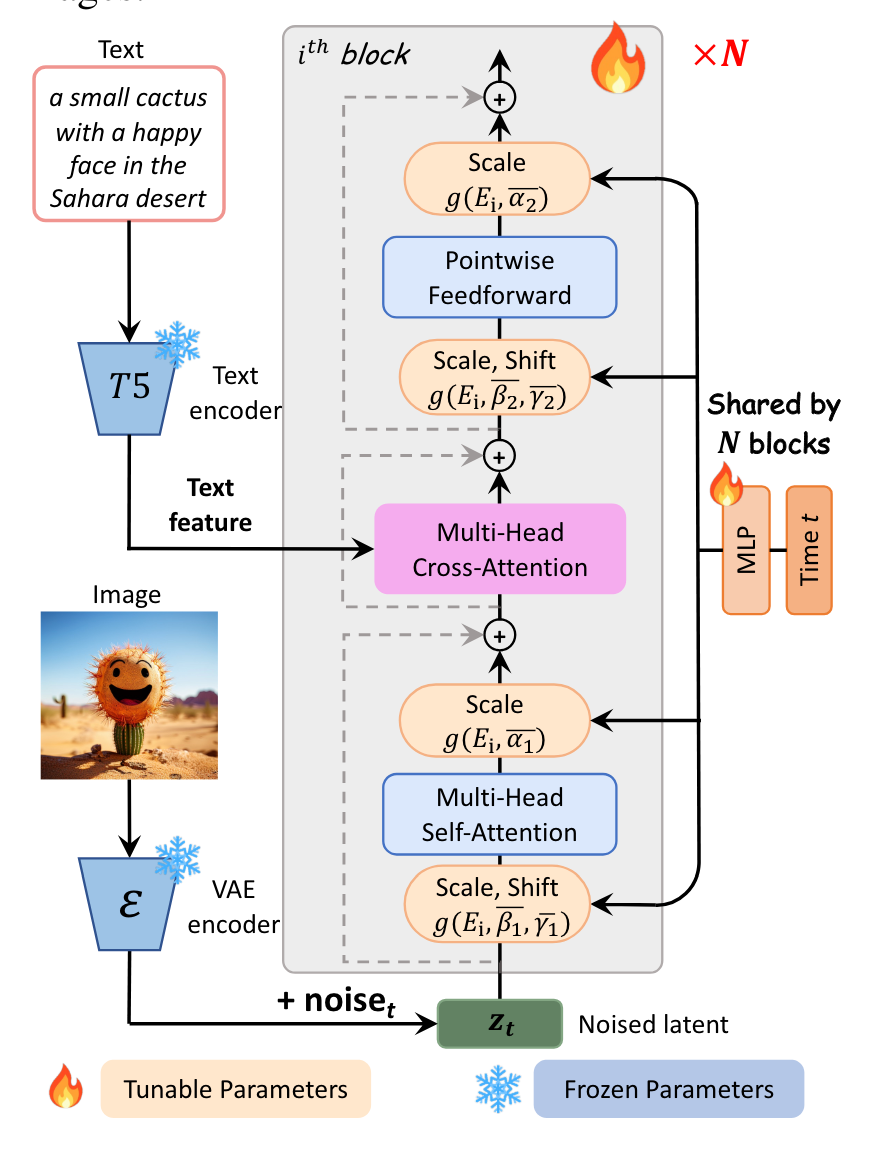


降低Attention计算复杂度
- Blog
- mamba:空间状态机
图像生成评估指标
Inception Score (IS)

然而,Inception Score 并不是完美的指标,它不能很好地捕捉到模式崩溃(mode collapse)的问题,即模型可能只生成少数几类图像但仍然获得高IS值。此外,IS依赖于预训练的Inception模型,这意味着它在某种程度上受限于Inception模型的性能和它在特定数据集上的训练情况。
Fréchet Inception Distance (FID)

Clip Score

R- Precision

面试问题
diffusion的采样方式有哪些?
确定性采样(DDIM),随机采样,条件采样
Pixel Diffusion有哪些?
lora推理过程有额外的计算吗?
在推理过程中,LoRA 的确会引入额外的计算步骤,因为它需要计算低秩矩阵与原始权重的组合。具体来说,LoRA 在预训练模型的权重矩阵 ( W ) 上应用两个较小的矩阵 ( A ) 和 ( B ) 的乘积,得到一个低秩矩阵 Δ W = A × B \Delta W = A \times B ΔW=A×B,然后将这个低秩矩阵添加到原始的权重矩阵 ( W ) 上,得到适应了新任务的权重矩阵 W + Δ W W + \Delta W W+ΔW。
stable diffusion不稳定的情况和原因?
- 文本描述的模糊性:如果提供给模型的文本描述过于模糊或含糊不清,模型可能难以理解预期的输出,从而生成与预期差异较大的图像。例如,一个模糊的描述如“一个美丽的场景”可能导致模型生成一系列非常不同的图像,因为“美丽”是一个主观且模糊的概念。
- 模型训练数据的局限性:Stable Diffusion模型的表现在很大程度上取决于其训练数据。如果模型在训练过程中没有接触到足够多样化的数据,或者特定主题的数据较少,那么在生成这些主题的图像时可能会表现不佳。
- 复杂或特定领域的文本描述:对于一些特定领域或非常复杂的文本描述,模型可能难以准确理解并生成匹配的图像。这是因为模型的文本理解能力受到其训练数据和内部表征的限制。
- 超参数设置不当:Stable Diffusion模型的性能也受到超参数设置的影响,包括采样步骤数、温度参数等。不适当的超参数设置可能导致生成过程不稳定,比如生成模糊的图像或细节丢失。
- 引导过程的挑战:在使用Stable Diffusion进行图像编辑或利用特定的引导技术(如CLIP引导)时,不恰当的引导或编辑策略可能导致生成结果与预期不符。
文本如何控制图像生成的?
文本没有权重是如何控制的?
Clip如何训练,如何推理的?
代码
- condition/uncondition的代码实现:https://github.com/Allenem/DDPM/blob/main/ddpm_conditional.py